Ankit Toshniwal, Siddarth Taneja, Amit Shukla, Karthik Ramasamy, Jignesh M. Patel*, Sanjeev Kulkarni,Jason Jackson, Krishna Gade, Maosong Fu, Jake Donham, Nikunj Bhagat, Sailesh Mittal, Dmitriy Ryaboy
Twitter , *University of Wisconsin – Madison
1、INTRODUCTION
Storm is a realtime fault-tolerant and distributed stream data processing system.
Storm is currently being used to run various critical computations in Twitter at scale, and in real-time.
(1)Scalable.The operations team needs to easily add or remove nodes from the Storm cluster without disrupting existing data flows through Storm topologies.
(2)Resilient.Fault-tolerance is crucial to Storm as it is often deployed on large clusters, and hardware components can fail.
(3)Extensible.Storm topologies may call arbitrary external functions, and thus needs a framework that allows extensibility.
(4)Efficient.Since Storm is used in real-time applications; it must have good performance characteristics.
(5)Easy to Administer.The operational team needs early warning tools and must be able to quickly point out the source of problems as they arise.
Origin:
1.STREAM: The Stanford Data Stream Management System.
2.Retrospective on Aurora.
3.Querying and Mining Data Streams: You Only Get One Look.
4. The Design of the Borealis Stream Processing Engine.
Similar:
1.S4 2.MillWheel 3.Samza 4. Spark Streaming 5.Photon
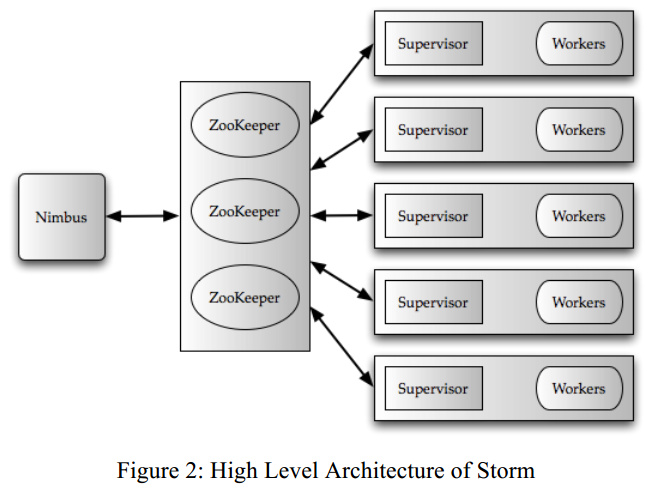
2、Data Model and Execution Architecture
Architecture:
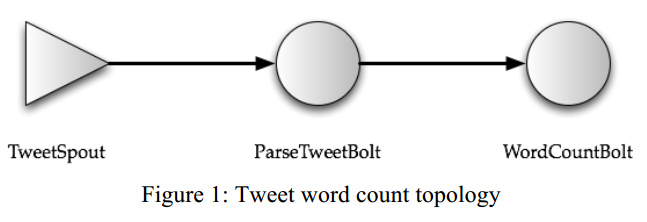
The basic Storm data processing architecture consists of streams of tuples flowing through topologies.
Spouts and Bolts:
Spouts:spouts are tuple sources for the topology .
Bolts:bolts process the incoming tuples and pass them to the next set of bolts downstream.
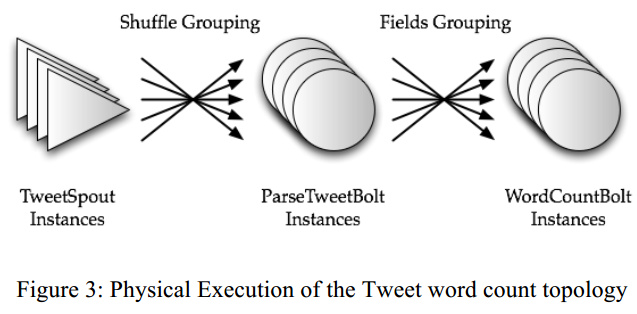
Storm supports the following types of partitioning strategies:
1. Shuffle grouping, which randomly partitions the tuples.
2. Fields grouping, which hashes on a subset of the tuple attributes/fields.
3. All grouping, which replicates the entire stream to all the consumer tasks.
4. Global grouping, which sends the entire stream to a single bolt.
5. Local grouping, which sends tuples to the consumer bolts in the same executor.
A topology can be considered as a logical query plan from a database systems perspective. As a part of the topology,the programmer specifies how many instances of each spout and bolt must be spawned.
Processing Semantics:
At least once semantics guarantees that each tuple that is input to the topology will be processed at least once.
With at most once semantics, each tuple is either processed once, or dropped in the case of a failure.
3、Storm in use @ Twitter
Overloaded Zookeeper:
| Configuration |
Configuration details |
Result |
| 1 |
Use an existing Zookeeper cluster at
Twitter that was also being used by
many other systems inside Twitter |
Quickly exceeded the amount of
clients that this Zookeeper
cluster could support |
| 2 |
Identical to the first one, except with
dedicated hardware for the Zookeeper
cluster |
Improved the number of workers
processes and topologies that run
in Storm cluster , but quicklyhit a
limit at around 300 workers per
cluster |
| 3 |
Changed the Zookeeper hardware and
configuration again: We used
database class hardware |
Scaled to approximately 1200
workers |
| 4 |
Changed the Kafka Spout code to
write its state to a key-value
store , also changed the
Storm core |
In favor of high availability and
high write performance |
Storm Overheads:
| The experiment |
Experimental
environment |
Support
message
reliability |
Input
consumption
(msgs/sec) |
CPU
utilization |
| 1 |
Write a Java program
that did not use
Storm1 machine |
no |
300K |
700% |
| 2 |
Storm topology
1 machine |
no |
300K |
660% |
| 3 |
Storm topology
3 machine |
yes |
300K |
924% |
Conclusion 1: Mitigated the concerns regarding Storm adding significant overhead compared to vanilla Java code that did the same computation.
Conclusion 2: Storm CPU costs related to the message reliability mechanism in Storm are nontrivial �.
Max Spout Tuning:
Storm topologies have a max spout pending parameter.
Problem :right value for this max spout pending parameter.
Solution:auto-tuning algorithm.
4、Conclusions and Future Work
Storm is a critical infrastructure at Twitter that powers many of the real-time data-driven decisions that are made at Twitter.
1.Automatically optimizing the topology statically and re-optimizing dynamically
2.Add exactonce semantics
3.Improve the visualization tools, improve the reliability of certain parts
4.Provide a better integration of Storm with Hadoop
5.Support a declarative query paradigm for Storm that still allows easy extensibility.
 ABCLearning
ABCLearning